")

共计 47250 个字符,预计需要花费 119 分钟才能阅读完成。
RDD 全称 Resilient Distributed DataSets,弹性的分布式数据集。是 Spark 的核心内容。
RDD 是只读的,不可变的数据集,也拥有很好的容错机制。他有 5 个主要特性
-A list of partitions 分片列表,数据能为切分才好做并行计算
-A function for computing each split 一个函数计算一个分片
-A list of dependencies on other RDDs 对其他 RDD 的依赖列表
-Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
RDD 可选的,key-value 型的 RDD,根据 hash 来分区
-Optionally, a list of preferred locations to compute each split on (e.g. blocklocations for
an HDFS file) 可选的,每一个分片的最佳计算位置
RDD 是 Spark 所有组件运行的底层系统,RDD 是一个容错的,并行的数据结构,它提供了丰富的数据操作和 API 接口
Spark 中的 RDD API


一个 RDD 可以包含多个分区。每个分区都是一个 dataset 片段。RDD 之间可以相互依赖
窄依赖:一一对应的关系,一个 RDD 分区只能被一个子 RDD 的分区使用的关系
宽依赖:一多对应关系,若多个子 RDD 分区都依赖同一个父 RDD 分区
如下 RDD 图览

在源码 packageorg.apache.spark.rdd.RDD 中有一些比较中的方法:
1)
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * 子类实现返回一组分区在这个 RDD。这种方法将只被调用一次,因此它是安全的, 它来实现一个耗时的计算。 */ protected def getPartitions: Array[Partition] |
这个方法返回多个 partition,存放在一个数字中
2)
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * 子类实现返回这个 RDD 如何取决于父 RDDS。这种方法将只被调用一次,因此它是安全的,它来实现一个耗时的计算。 * */ protected def getDependencies: Seq[Dependency[_]] = deps |
它返回一个依赖关系的 Seq 集合
3)
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. * 子类实现的计算一个给定的分区。 */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T] |
每个 RDD 都有一个对应的具体计算函数
4)
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil |
获取 partition 的首选位置,这是分区策略。
RDD Transformations and action
RDD 数据操作主要有两个动作:
Transformations(转换) | map(f : T) U) : RDD[T] ) RDD[U] |
Action(动作) | count() : RDD[T] ) Long |
先看下 Transformations 部分
// Transformations (return a new RDD)
/** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this, sc.clean(f))
/** * Return a new RDD by first applying a function to all elements of this * RDD, and then flattening the results. */ def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = new FlatMappedRDD(this, sc.clean(f))
/** * Return a new RDD containing only the elements that satisfy a predicate. */ def filter(f: T => Boolean): RDD[T] = new FilteredRDD(this, sc.clean(f)) …… |
Map
/** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this, sc.clean(f)) |
返回一个 MappedRDD,它继承 RDD 并重写了两个方法 getPartitions、compute
第一个方法 getPartitions,他获取第一个父 RDD,并获取分片数组
override def getPartitions: Array[Partition] = firstParent[T].partitions |
第二个方法 compute,将根据 map 参数内容来遍历 RDD 分区
override def compute(split: Partition, context: TaskContext) = firstParent[T].iterator(split, context).map(f) |
filter
/** * Return a new RDD containing only the elements that satisfy a predicate. */ def filter(f: T => Boolean): RDD[T] = new FilteredRDD(this, sc.clean(f)) |
Filter 是一个过滤操作,比如 mapRDD.filter(_ >1)
Union
/** * Return the union of this RDD and another one. Any identical elements will appear multiple * times (use `.distinct()` to eliminate them). */ def union(other: RDD[T]): RDD[T] = new UnionRDD(sc, Array(this, other)) |
多个 RDD 组成成一个新 RDD,它重写了 RDD 的 5 个方法 getPartitions、getDependencies、compute、getPreferredLocations、clearDependencies
从 getPartitions、getDependencies 中可以看出它应该是一组宽依赖关系
override def getDependencies: Seq[Dependency[_]] = { val deps = new ArrayBuffer[Dependency[_]] var pos = 0 for (rdd <- rdds) { deps += new RangeDependency(rdd, 0, pos, rdd.partitions.size) pos += rdd.partitions.size } deps } |
groupBy
/** * Return an RDD of grouped items. Each group consists of a key and a sequence of elements * mapping to that key. * * Note: This operation may be very expensive. If you are grouping in order to perform an * aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]] * or [[PairRDDFunctions.reduceByKey]] will provide much better performance. */ def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = groupBy[K](f, defaultPartitioner(this)) |
根据参数分组,这又产生了一个新的 RDD
Action
Count
/** * Return the number of elements in the RDD. */ def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum |
跟踪代码,在 runJob 方法中调用了 dagScheduler.runJob。而在 DAGScheduler,将提交到作业调度器,并获得 JobWaiter 对象返回。该 JobWaiter 对象可以用来阻塞,直到任务完成执行或可以用来取消作业。
RDD 中的任务调度

从这个图中:
RDD Object 产生 DAG,然后进入 DAGScheduler 阶段:
1、DAGScheduler 是面向 Stage 的高层次调度器,DAGScheduler 会将 DAG 拆分成很多个 tasks,而一组 tasks 就是图中的 stage。
2、每一次 shuffle 的过程就会产生一个新的 stage。DAGScheduler 会有 RDD 记录磁盘的物· 理化操作,为了获得最有 tasks,DAGSchulder 会先查找本地 tasks。
3、DAGScheduler 还要监控 shuffle 产生的失败任务,如果还得重启
DAGScheduler 划分 stage 后,会以 TaskSet 为单位把任务提交给 TaskScheduler:
1、一个 TaskScheduler 只为一个 sparkConext 服务。
2、当接收到 TaskSet 后,它会把任务提交给 Worker 节点的 Executor 中去运行。失败的任务
由 TaskScheduler 监控重启。
Executor 是以多线程的方式运行,每个线程都负责一个任务。
接下来跟踪一个 spark 提供的例子源码:
源码 packageorg.apache.spark.examples.SparkPi
def main(args: Array[String]) { // 设置一个应用名称 (用于在 Web UI 中显示) val conf = new SparkConf().setAppName(“Spark Pi”) // 实例化一个 SparkContext val spark = new SparkContext(conf) // 转成数据 val slices = if (args.length > 0) args(0).toInt else 2 val n = 100000 * slices val count = spark.parallelize(1 to n, slices).map {i => val x = random * 2 – 1 val y = random * 2 – 1 if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _) println(“Pi is roughly ” + 4.0 * count / n) spark.stop() } |
代码中的 parallelize 是一个并行化的延迟加载,跟踪源码
/** Distribute a local Scala collection to form an RDD. * 从 RDD 中分配一个本地的 scala 集合 * @note Parallelize acts lazily. If `seq` is a mutable collection and is * altered after the call to parallelize and before the first action on the * RDD, the resultant RDD will reflect the modified collection. Pass a copy of * the argument to avoid this. */ def parallelize[T: ClassTag](seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = { new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]()) } |
它调用了 RDD 中的 map,上面说过的 map 是一个转换过程,将生成一个新的 RDD。最后 reduce。
在 shell 中弄一个单词统计例子:
scala> val rdd = sc.textFile(“hdfs://192.168.0.245:8020/test/README.md”) 14/12/18 01:12:26 INFO storage.MemoryStore: ensureFreeSpace(82180) called with curMem=331133, maxMem=280248975 14/12/18 01:12:26 INFO storage.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 80.3 KB, free 266.9 MB) rdd: org.apache.spark.rdd.RDD[String] = hdfs://192.168.0.245:8020/test/README.md MappedRDD[7] at textFile at <console>:12
scala> rdd.toDebugString 14/12/18 01:12:29 INFO mapred.FileInputFormat: Total input paths to process : 1 res3: String = (1) hdfs://192.168.0.245:8020/test/README.md MappedRDD[7] at textFile at <console>:12 | hdfs://192.168.0.245:8020/test/README.md HadoopRDD[6] at textFile at <console>:12
|
Sc 是从 hdfs 中读取数据,那在 debugString 中他就转换成了 HadoopRDD
scala> val result = rdd.flatMap(_.split(” “)).map((_,1)).reduceByKey(_+_).collect 14/12/18 01:14:51 INFO spark.SparkContext: Starting job: collect at <console>:14 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Registering RDD 9 (map at <console>:14) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Got job 0 (collect at <console>:14) with 1 output partitions (allowLocal=false) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Final stage: Stage 0(collect at <console>:14) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Parents of final stage: List(Stage 1) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Missing parents: List(Stage 1) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Submitting Stage 1 (MappedRDD[9] at map at <console>:14), which has no missing parents 14/12/18 01:14:51 INFO storage.MemoryStore: ensureFreeSpace(3440) called with curMem=413313, maxMem=280248975 14/12/18 01:14:51 INFO storage.MemoryStore: Block broadcast_4 stored as values in memory (estimated size 3.4 KB, free 266.9 MB) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from Stage 1 (MappedRDD[9] at map at <console>:14) 14/12/18 01:14:51 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 14/12/18 01:14:51 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 0, localhost, ANY, 1185 bytes) 14/12/18 01:14:51 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 0) 14/12/18 01:14:51 INFO rdd.HadoopRDD: Input split: hdfs://192.168.0.245:8020/test/README.md:0+4811 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 14/12/18 01:14:52 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 0). 1860 bytes result sent to driver 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Stage 1 (map at <console>:14) finished in 1.450 s 14/12/18 01:14:53 INFO scheduler.DAGScheduler: looking for newly runnable stages 14/12/18 01:14:53 INFO scheduler.DAGScheduler: running: Set() 14/12/18 01:14:53 INFO scheduler.DAGScheduler: waiting: Set(Stage 0) 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 0) in 1419 ms on localhost (1/1) 14/12/18 01:14:53 INFO scheduler.DAGScheduler: failed: Set() 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Missing parents for Stage 0: List() 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Submitting Stage 0 (ShuffledRDD[10] at reduceByKey at <console>:14), which is now runnable 14/12/18 01:14:53 INFO storage.MemoryStore: ensureFreeSpace(2112) called with curMem=416753, maxMem=280248975 14/12/18 01:14:53 INFO storage.MemoryStore: Block broadcast_5 stored as values in memory (estimated size 2.1 KB, free 266.9 MB) 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from Stage 0 (ShuffledRDD[10] at reduceByKey at <console>:14) 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 948 bytes) 14/12/18 01:14:53 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 1) 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: maxBytesInFlight: 50331648, targetRequestSize: 10066329 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: Started 0 remote fetches in 5 ms 14/12/18 01:14:53 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 1). 8680 bytes result sent to driver 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Stage 0 (collect at <console>:14) finished in 0.108 s 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 1) in 99 ms on localhost (1/1) 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 14/12/18 01:14:53 INFO spark.SparkContext: Job finished: collect at <console>:14, took 1.884598939 s result: Array[(String, Int)] = Array((For,5), (Programs,1), (gladly,1), (Because,1), (The,1), (agree,1), (cluster.,1), (webpage,1), (its,1), (-Pyarn,3), (under,2), (legal,1), (APIs,1), (1.x,,1), (computation,1), (Try,1), (MRv1,,1), (have,2), (Thrift,2), (add,2), (through,1), (several,1), (This,2), (Whether,1), (“yarn-cluster”,1), (%,2), (graph,1), (storage,1), (To,2), (setting,2), (any,2), (Once,1), (application,1), (JDBC,3), (use:,1), (prefer,1), (SparkPi,2), (engine,1), (version,3), (file,1), (documentation,,1), (processing,,2), (Along,1), (the,28), (explicitly,,1), (entry,1), (author.,1), (are,2), (systems.,1), (params,1), (not,2), (different,1), (refer,1), (Interactive,2), (given.,1), (if,5), (`-Pyarn`:,1), (build,3), (when,3), (be,2), (Tests,1), (file’s,1), (Apache,6), (./bin/run-e… |
根据空格来区分单词后,各个单词的统计结果
更多详情见请继续阅读下一页的精彩内容 :http://www.linuxidc.com/Linux/2016-03/129062p2.htm
这里主要说明作业提交的过程源码。SparkSubmit 在 org.apache.spark.deploy 中,submit 是一个单独的进程,首先查看它的 main 方法:

createLaunchEnv 方法中设置了一些配置参数:如返回值、集群模式、运行环境等。这里主要查看 Client 的集群模式。下面看下作业提交序列图:

Client
Client 的启动方法 preStart。

Client 是一个 actor,Client 提交任务,首先需要封装好 DriverDescription 参数。包括 jar 文件 url、momory、cpu cores 等。然后向 Master 发送 RequestSubmitDriver 消息。
Master
Master 中接收 RequestSubmitDriver 消息的处理:

这里主要看下 schedule 这个方法:



上面源码中。主要看;两个方法 launchDriver、launchExecutor
launchDriver
launchDriver:是让 worker 来启动 driver

launchExecutor

Worker
Master 向 Worker 发送了 LaunchDriver 和 LaunchExecutor。这里在就跟踪 Worker 下怎么处理 Master 发送的这两个消息。
LaunchDriver 启动 driver

这里启动了 driver。而它在启动的时候 就是创建目录然后下载 jar 包然后记载一些参数,最后向 work 发送 worker !DriverStateChanged(driverId, state, finalException)。Worker 接收到 DriverStateChanged 后将消息发给 Master。最后 Master 接收到这个消息,则移除 driver
LaunchExecutor
Worker 创建一个 ExecutorRunner 线程,ExecutorRunner 会启动 ExecutorBackend 进程

这里真正的执行方法在 ExecutorRunner 中的 fetchAndRunExecutor 方法中。
接下来从一张流程图中简要描述了作业提交的流程。

1)客户端启动后直接运行用户程序,启动 Driver 相关的工作:DAGScheduler 和 BlockManagerMaster 等。
2)客户端的 Driver 向 Master 注册。
3)Master 会让 Worker 启动 Exeuctor。
4)Worker 创建一个 ExecutorRunner 线程,ExecutorRunner 会启动 ExecutorBackend 进程。ExecutorBackend 启动后会向 Driver 的 SchedulerBackend 注册。
5)Driver 的 DAGScheduler 解析作业并生成相应的 Stage,每个 Stage 包含的 Task 通过 TaskScheduler 分配给 Executor 执行。所有 stage 都完成后作业结束。
RDD 全称 Resilient Distributed DataSets,弹性的分布式数据集。是 Spark 的核心内容。
RDD 是只读的,不可变的数据集,也拥有很好的容错机制。他有 5 个主要特性
-A list of partitions 分片列表,数据能为切分才好做并行计算
-A function for computing each split 一个函数计算一个分片
-A list of dependencies on other RDDs 对其他 RDD 的依赖列表
-Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
RDD 可选的,key-value 型的 RDD,根据 hash 来分区
-Optionally, a list of preferred locations to compute each split on (e.g. blocklocations for
an HDFS file) 可选的,每一个分片的最佳计算位置
RDD 是 Spark 所有组件运行的底层系统,RDD 是一个容错的,并行的数据结构,它提供了丰富的数据操作和 API 接口
Spark 中的 RDD API
一个 RDD 可以包含多个分区。每个分区都是一个 dataset 片段。RDD 之间可以相互依赖
窄依赖:一一对应的关系,一个 RDD 分区只能被一个子 RDD 的分区使用的关系
宽依赖:一多对应关系,若多个子 RDD 分区都依赖同一个父 RDD 分区
如下 RDD 图览
在源码 packageorg.apache.spark.rdd.RDD 中有一些比较中的方法:
1)
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * 子类实现返回一组分区在这个 RDD。这种方法将只被调用一次,因此它是安全的, 它来实现一个耗时的计算。 */ protected def getPartitions: Array[Partition] |
这个方法返回多个 partition,存放在一个数字中
2)
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * 子类实现返回这个 RDD 如何取决于父 RDDS。这种方法将只被调用一次,因此它是安全的,它来实现一个耗时的计算。 * */ protected def getDependencies: Seq[Dependency[_]] = deps |
它返回一个依赖关系的 Seq 集合
3)
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. * 子类实现的计算一个给定的分区。 */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T] |
每个 RDD 都有一个对应的具体计算函数
4)
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil |
获取 partition 的首选位置,这是分区策略。
RDD Transformations and action
RDD 数据操作主要有两个动作:
Transformations(转换) | map(f : T) U) : RDD[T] ) RDD[U] |
Action(动作) | count() : RDD[T] ) Long |
先看下 Transformations 部分
// Transformations (return a new RDD)
/** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this, sc.clean(f))
/** * Return a new RDD by first applying a function to all elements of this * RDD, and then flattening the results. */ def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = new FlatMappedRDD(this, sc.clean(f))
/** * Return a new RDD containing only the elements that satisfy a predicate. */ def filter(f: T => Boolean): RDD[T] = new FilteredRDD(this, sc.clean(f)) …… |
Map
/** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this, sc.clean(f)) |
返回一个 MappedRDD,它继承 RDD 并重写了两个方法 getPartitions、compute
第一个方法 getPartitions,他获取第一个父 RDD,并获取分片数组
override def getPartitions: Array[Partition] = firstParent[T].partitions |
第二个方法 compute,将根据 map 参数内容来遍历 RDD 分区
override def compute(split: Partition, context: TaskContext) = firstParent[T].iterator(split, context).map(f) |
filter
/** * Return a new RDD containing only the elements that satisfy a predicate. */ def filter(f: T => Boolean): RDD[T] = new FilteredRDD(this, sc.clean(f)) |
Filter 是一个过滤操作,比如 mapRDD.filter(_ >1)
Union
/** * Return the union of this RDD and another one. Any identical elements will appear multiple * times (use `.distinct()` to eliminate them). */ def union(other: RDD[T]): RDD[T] = new UnionRDD(sc, Array(this, other)) |
多个 RDD 组成成一个新 RDD,它重写了 RDD 的 5 个方法 getPartitions、getDependencies、compute、getPreferredLocations、clearDependencies
从 getPartitions、getDependencies 中可以看出它应该是一组宽依赖关系
override def getDependencies: Seq[Dependency[_]] = { val deps = new ArrayBuffer[Dependency[_]] var pos = 0 for (rdd <- rdds) { deps += new RangeDependency(rdd, 0, pos, rdd.partitions.size) pos += rdd.partitions.size } deps } |
groupBy
/** * Return an RDD of grouped items. Each group consists of a key and a sequence of elements * mapping to that key. * * Note: This operation may be very expensive. If you are grouping in order to perform an * aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]] * or [[PairRDDFunctions.reduceByKey]] will provide much better performance. */ def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = groupBy[K](f, defaultPartitioner(this)) |
根据参数分组,这又产生了一个新的 RDD
Action
Count
/** * Return the number of elements in the RDD. */ def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum |
跟踪代码,在 runJob 方法中调用了 dagScheduler.runJob。而在 DAGScheduler,将提交到作业调度器,并获得 JobWaiter 对象返回。该 JobWaiter 对象可以用来阻塞,直到任务完成执行或可以用来取消作业。
RDD 中的任务调度
从这个图中:
RDD Object 产生 DAG,然后进入 DAGScheduler 阶段:
1、DAGScheduler 是面向 Stage 的高层次调度器,DAGScheduler 会将 DAG 拆分成很多个 tasks,而一组 tasks 就是图中的 stage。
2、每一次 shuffle 的过程就会产生一个新的 stage。DAGScheduler 会有 RDD 记录磁盘的物· 理化操作,为了获得最有 tasks,DAGSchulder 会先查找本地 tasks。
3、DAGScheduler 还要监控 shuffle 产生的失败任务,如果还得重启
DAGScheduler 划分 stage 后,会以 TaskSet 为单位把任务提交给 TaskScheduler:
1、一个 TaskScheduler 只为一个 sparkConext 服务。
2、当接收到 TaskSet 后,它会把任务提交给 Worker 节点的 Executor 中去运行。失败的任务
由 TaskScheduler 监控重启。
Executor 是以多线程的方式运行,每个线程都负责一个任务。
接下来跟踪一个 spark 提供的例子源码:
源码 packageorg.apache.spark.examples.SparkPi
def main(args: Array[String]) { // 设置一个应用名称 (用于在 Web UI 中显示) val conf = new SparkConf().setAppName(“Spark Pi”) // 实例化一个 SparkContext val spark = new SparkContext(conf) // 转成数据 val slices = if (args.length > 0) args(0).toInt else 2 val n = 100000 * slices val count = spark.parallelize(1 to n, slices).map {i => val x = random * 2 – 1 val y = random * 2 – 1 if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _) println(“Pi is roughly ” + 4.0 * count / n) spark.stop() } |
代码中的 parallelize 是一个并行化的延迟加载,跟踪源码
/** Distribute a local Scala collection to form an RDD. * 从 RDD 中分配一个本地的 scala 集合 * @note Parallelize acts lazily. If `seq` is a mutable collection and is * altered after the call to parallelize and before the first action on the * RDD, the resultant RDD will reflect the modified collection. Pass a copy of * the argument to avoid this. */ def parallelize[T: ClassTag](seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = { new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]()) } |
它调用了 RDD 中的 map,上面说过的 map 是一个转换过程,将生成一个新的 RDD。最后 reduce。
在 shell 中弄一个单词统计例子:
scala> val rdd = sc.textFile(“hdfs://192.168.0.245:8020/test/README.md”) 14/12/18 01:12:26 INFO storage.MemoryStore: ensureFreeSpace(82180) called with curMem=331133, maxMem=280248975 14/12/18 01:12:26 INFO storage.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 80.3 KB, free 266.9 MB) rdd: org.apache.spark.rdd.RDD[String] = hdfs://192.168.0.245:8020/test/README.md MappedRDD[7] at textFile at <console>:12
scala> rdd.toDebugString 14/12/18 01:12:29 INFO mapred.FileInputFormat: Total input paths to process : 1 res3: String = (1) hdfs://192.168.0.245:8020/test/README.md MappedRDD[7] at textFile at <console>:12 | hdfs://192.168.0.245:8020/test/README.md HadoopRDD[6] at textFile at <console>:12
|
Sc 是从 hdfs 中读取数据,那在 debugString 中他就转换成了 HadoopRDD
scala> val result = rdd.flatMap(_.split(” “)).map((_,1)).reduceByKey(_+_).collect 14/12/18 01:14:51 INFO spark.SparkContext: Starting job: collect at <console>:14 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Registering RDD 9 (map at <console>:14) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Got job 0 (collect at <console>:14) with 1 output partitions (allowLocal=false) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Final stage: Stage 0(collect at <console>:14) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Parents of final stage: List(Stage 1) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Missing parents: List(Stage 1) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Submitting Stage 1 (MappedRDD[9] at map at <console>:14), which has no missing parents 14/12/18 01:14:51 INFO storage.MemoryStore: ensureFreeSpace(3440) called with curMem=413313, maxMem=280248975 14/12/18 01:14:51 INFO storage.MemoryStore: Block broadcast_4 stored as values in memory (estimated size 3.4 KB, free 266.9 MB) 14/12/18 01:14:51 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from Stage 1 (MappedRDD[9] at map at <console>:14) 14/12/18 01:14:51 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 14/12/18 01:14:51 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 0, localhost, ANY, 1185 bytes) 14/12/18 01:14:51 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 0) 14/12/18 01:14:51 INFO rdd.HadoopRDD: Input split: hdfs://192.168.0.245:8020/test/README.md:0+4811 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 14/12/18 01:14:51 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 14/12/18 01:14:52 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 0). 1860 bytes result sent to driver 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Stage 1 (map at <console>:14) finished in 1.450 s 14/12/18 01:14:53 INFO scheduler.DAGScheduler: looking for newly runnable stages 14/12/18 01:14:53 INFO scheduler.DAGScheduler: running: Set() 14/12/18 01:14:53 INFO scheduler.DAGScheduler: waiting: Set(Stage 0) 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 0) in 1419 ms on localhost (1/1) 14/12/18 01:14:53 INFO scheduler.DAGScheduler: failed: Set() 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Missing parents for Stage 0: List() 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Submitting Stage 0 (ShuffledRDD[10] at reduceByKey at <console>:14), which is now runnable 14/12/18 01:14:53 INFO storage.MemoryStore: ensureFreeSpace(2112) called with curMem=416753, maxMem=280248975 14/12/18 01:14:53 INFO storage.MemoryStore: Block broadcast_5 stored as values in memory (estimated size 2.1 KB, free 266.9 MB) 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from Stage 0 (ShuffledRDD[10] at reduceByKey at <console>:14) 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 948 bytes) 14/12/18 01:14:53 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 1) 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: maxBytesInFlight: 50331648, targetRequestSize: 10066329 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 14/12/18 01:14:53 INFO storage.BlockFetcherIterator$BasicBlockFetcherIterator: Started 0 remote fetches in 5 ms 14/12/18 01:14:53 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 1). 8680 bytes result sent to driver 14/12/18 01:14:53 INFO scheduler.DAGScheduler: Stage 0 (collect at <console>:14) finished in 0.108 s 14/12/18 01:14:53 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 1) in 99 ms on localhost (1/1) 14/12/18 01:14:53 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 14/12/18 01:14:53 INFO spark.SparkContext: Job finished: collect at <console>:14, took 1.884598939 s result: Array[(String, Int)] = Array((For,5), (Programs,1), (gladly,1), (Because,1), (The,1), (agree,1), (cluster.,1), (webpage,1), (its,1), (-Pyarn,3), (under,2), (legal,1), (APIs,1), (1.x,,1), (computation,1), (Try,1), (MRv1,,1), (have,2), (Thrift,2), (add,2), (through,1), (several,1), (This,2), (Whether,1), (“yarn-cluster”,1), (%,2), (graph,1), (storage,1), (To,2), (setting,2), (any,2), (Once,1), (application,1), (JDBC,3), (use:,1), (prefer,1), (SparkPi,2), (engine,1), (version,3), (file,1), (documentation,,1), (processing,,2), (Along,1), (the,28), (explicitly,,1), (entry,1), (author.,1), (are,2), (systems.,1), (params,1), (not,2), (different,1), (refer,1), (Interactive,2), (given.,1), (if,5), (`-Pyarn`:,1), (build,3), (when,3), (be,2), (Tests,1), (file’s,1), (Apache,6), (./bin/run-e… |
根据空格来区分单词后,各个单词的统计结果
更多详情见请继续阅读下一页的精彩内容 :http://www.linuxidc.com/Linux/2016-03/129062p2.htm
下面主要说明作业提交的的具体运行环境,这里从 SparkContext 中的 runJob 方法开始跟踪它的源码过程。下面的图简要的描述了 Job 运行的过程

runJob 的源码如下:

这里主要有三个函数:
Clean(func):主要是清理关闭一些内容,比如序列化。
runJob(…):将任务提交给 DagScheduler。
doCheckpoint():保存当前 RDD,在 Job 完成之后调用父 rdd。
这里主要看 runJob 方法
DagScheduler
跟踪源码,进入了 DagScheduler 的 runJob 方法。这这里方法中会直接提交 Job,然后等待返回结果。成功时 JobSucceeded 什么都不做,失败则抛出异常。
进去源码 submitJob 方法,这方法提交作业到调度器,源码如下:

跟踪源码:eventProcessActor 是 DagScheduler 的事件驱动也是一个 Actor。这里发送了一个消息 eventProcessActor !JobSubmitted:

程序中调用了 handleJobSubmitted 方法

上面源码中:
1)newStage 实例化一个 Stage。Stage 就是一组 Tasks。
2)创建 ActiveJob,是跟踪 DAGScheduler 中正在活动的 Job
3)判断是否在本地运行。shouldRunLocally 为 true 调用 runLocally,false 则是 submitStage
接下来在本地 RDD 运行的 Job,runLocally 方法:

这个方法启动了一个线程,里面运行了 runLocallyWithinThread 方法

下面具体看下 submitStage 方法:

这里是一个递归提交的过程,如果有父 stage 则先提交,然后将自己放置等待队列。下面网上的一张图能很好的表述这段代码:

在你递归完所有的 stage 后,开始提交等待状态的 stages。也就是 submitWaitingStages 这个方法了:

当 stage 没有任何父 stage 依赖的时候,跟踪源码会进入 submitMissingTasks。这里就开始提交任务了。提交任务的时候需要测试序列化的 tasks,如果不需要则直接通过 SparkListenerStageSubmitted 发布 tasks。最后,将会以 TaskSet 的方式将任务集合提交到 TaskScheduler。

TaskScheduler
从上面的源码一路跟踪,到了 TaskScheduler 了。TaskScheduler 有多个实现类

这里进入到了 TaskSchedulerImpl 这个实现类。OK,看看它如何实现 submitTasks 这个方法的:

1)new 了一个 TaskSetManager。TaskSetManager 管理和跟踪 TaskSet。失败的任务他会重新启动他,当然重启的次数是有限。这个有 TaskSetManager 的构造参数 maxTaskFailures 决定。
2)添加任务调度模式。Spark 中提供了两种调度模式 FIFO 和 FAIR,默认是 FIFO。

具体来看看这个调度方法。

FIFO 是先进先出,这里将作业集添加到调度队列中去了。
3)backend.reviveOffers()。这个 backen 是 CoarseGrainedSchedulerBackend。这是一个调度器接口,他会等待 Executors 通过 AKKA 来连接他。

接着进入 DriverActor 的事件处理方法中去 receiveWithLogging,ReviveOffers 消息调用了 makeOffers()。源码如下:

源码中有两个方法一个是 resourceOffers。然后是 launchTasks。
resourceOffers 方法会从 workers 中随机抽出一些来执行任务,然后通过 TaskSetManager 找出和 Worker 在一起的 Task,最后打包成 TaskDescription 返回源码如下:


接下来看 launchTasks 方法了。该方法中最重要的一句就是:
executorActor(task.executorId) !LaunchTask(new SerializableBuffer(serializedTask))
excutorActor 是在 CoarseGrainedExecutorBackend 的 RegisteredExecutor 注册事件中,通过 SparkDeploySchedulerBackend 启动的 AppClient。而在 AppClient 内部启动了一个 AppActor,AppActor 想 Master 发送注册 APP 信息。

而在 Master 中对 RegisterApolication 事件是这样处理的:

Worker
LaunchExecutor
任务最终会发送到 Worker 中去处理,而接收处理的事件就是 LauchExecutor 了。处理过程如下面源码:

源码最后又向 Master 发送了 ExecutorStateChanged
Master 将时间转发给 Driver,如果果是 Executor 运行结束,从相应的映射关系里面删除。
CoarseGrainedExecutorBackend
最后发布任务是 CoarseGrainedExecutorBackend 中的 LaunchTask 事件。源码如下:

Executor
最后的任务执行 Executor!





用户提交的 Job 到 DAGScheduler 后,会封装成 ActiveJob,同时启动 JobWaiter 监听作业的完成情况。同时依据 job 中 RDD 的 dependency 和 dependency 属性 (NarrowDependency,ShufflerDependecy),DAGScheduler 会根据依赖关系的先后产生出不同的 stage DAG(result stage, shuffle map stage)。在每一个 stage 内部,根据 stage 产生出相应的 task,包括 ResultTask 或是 ShuffleMapTask,这些 task 会根据 RDD 中 partition 的数量和分布,产生出一组相应的 task,并将其包装为 TaskSet 提交到 TaskScheduler 上去。
在上面有从作业提交、作业运行的例子上分析查看了源码。这一章从 scheduler 各个类的具体方法阅读源码。
DAGScheduler
DAGScheduler 是高层级别的调度器。实现了 stage-oriented 调度。它计算一个 DAG 中 stage 的工作。并将这些 stage 输出落地物化。最终提交 stage 以 taskSet 方式提交给 TaskScheduler。DAGScheduler 需要接收上下层的消息,它也是一个 actor。这里主要看看他的一些事件处理。一下是的所处理的事件。

JobSubmitted


进入 submitStage 方法。submitStage 提交 stage,第一个提交的是没有父依赖关系的。

如果计算中发现当前的 stage 没有任何的依赖关系。则直接提交 task。
源码中的 getMissingParentStages 是获取父 stage。源码如下:

Ok 继续 submitStage,进入 submitMissingTasks 方法。该方法将 stage 根据 parition 拆分成 task。然后生成 TaskSet,并提交到 TaskScheduler。该方法在之前有贴出来过,这里就不贴出来了。
DAGScheduler 的主要功能:
1、接收用户提交的 job。
2、以 stage 的形式划分 job,并记录物化的 stage。在 stage 内产生的 task 以 taskSet 的方式提交给 taskScheduler。
TaskScheduler
TaskScheduler 低级别的任务调度程序的接口,目前由 TaskSchedulerImpl 完全实现。该接口允许插入不同的任务调度。TaskScheduler 接收 DAGScheduler 提交的 taskSet,并负责发送任务到集群上运行。
TaskScheduler 会根据部署方式而选择不同的 SchedulerBackend 来处理。针对不同部署方式会有不同的 TaskScheduler 与 SchedulerBackend 进行组合:
l Local 模式:TaskSchedulerImpl+ LocalBackend
l Spark 集群模式:TaskSchedulerImpl+ SparkDepolySchedulerBackend
l Yarn-Cluster 模式:YarnClusterScheduler + CoarseGrainedSchedulerBackend
l Yarn-Client 模式:YarnClientClusterScheduler + YarnClientSchedulerBackend
TaskScheduler 类负责任务调度资源的分配,SchedulerBackend 负责与 Master、Worker 通信收集 Worker 上分配给该应用使用的资源情况。
TaskSchedulerImpl
TaskSchedulerImpl 类就是负责为 Task 分配资源的。在 CoarseGrainedSchedulerBackend 获取到可用资源后就会通过 makeOffers 方法通知 TaskSchedulerImpl 对资源进行分配。
TaskSchedulerImpl 的 resourceOffers 方法就是负责为 Task 分配计算资源的,在为 Task 分配好资源后又会通过 lauchTasks 方法发送 LaunchTask 消息通知 Worker 上的 Executor 执行 Task。
下面看下 TaskSchedulerImpl 中的几个方法。
initialize:

initialize 方法主要就是初始化选择调度模式,这个可以由用户自己配置。
Start

submitTasks

TaskScheduler 中实际执行 task 时会调用 Backend.reviveOffers,在 spark 内有多个不同的 backend:

Stage
一个 stage 是一组由相同函数计算出来的任务集合,它运行 spark 上的 job。这里所有的任务都有相同的 shuffle 依赖。每个 stage 都是 map 函数计算,shuffle 随机产生的,在这种情况下,它的任务的结果被输给 stage,或者其返回一个 stage,在这种情况下,它的任务直接计算发起的作业的动作(例如,count()),save() 等)。都是 ShuffleMapStage 我们也可以跟踪每个节点上的输出分区。
Stage 的构造如下:

Task
Task: 一个执行单元,在 Spark 有两种实现:
org.apache.spark.scheduler.ShuffleMapTask
org.apache.spark.scheduler.ResultTask
一个 Spark 工作会包含一个或者多个 stages。一个 ResultTask 执行任务,并将任务输出 driver 应用。一个 ShuffleMapTask 执行的任务,并把任务输出到多个 buckets(基于任务的分区)
TaskSet
由 TaskScheduler 提交的一组 Task 集合
TaskSetManager
在 TaskSchedulerImpl 单内使用 taskset 调度任务. 此类跟踪每个任务,重试任务如果失败(最多的有限次数),并经由延迟调度处理局部性感知调度此使用 taskset。其主要接口有它 resourceOffer,它要求使用 taskset 是否愿意在一个节点上运行一个任务,statusUpdate,它告诉它其任务之一状态发生了改变

方法 addPendingTask:
添加一个任务的所有没有被执行的任务列表,它是 PendingTask。源码如下。

resourceOffer
解决如何在 taskset 内部 schedule 一个 task。源码如下:


Conf
Property Name | Default | Meaning |
spark.task.cpus | 1 | Number of cores to allocate for each task. |
spark.task.maxFailures | 4 | Number of individual task failures before giving up on the job. Should be greater than or equal to 1. Number of allowed retries = this value – 1. |
spark.scheduler.mode | FIFO | The scheduling mode between jobs submitted to the same SparkContext. Can be set to FAIR to use fair sharing instead of queueing jobs one after another. Useful for multi-user services. |
spark.cores.max | (not set) | When running on a standalone deploy cluster or aMesos cluster in “coarse-grained” sharing mode, the maximum amount of CPU cores to request for the application from across the cluster (not from each machine). If not set, the default will be spark.deploy.defaultCores on Spark’s standalone cluster manager, or infinite (all available cores) on Mesos. |
spark.mesos.coarse | false | If set to “true”, runs over Mesos clusters in “coarse-grained” sharing mode, where Spark acquires one long-lived Mesos task on each machine instead of one Mesos task per Spark task. This gives lower-latency scheduling for short queries, but leaves resources in use for the whole duration of the Spark job. |
spark.speculation | false | If set to “true”, performs speculative execution of tasks. This means if one or more tasks are running slowly in a stage, they will be re-launched. |
spark.speculation.interval | 100 | How often Spark will check for tasks to speculate, in milliseconds. |
spark.speculation.quantile | 0.75 | Percentage of tasks which must be complete before speculation is enabled for a particular stage. |
spark.speculation.multiplier | 1.5 | How many times slower a task is than the median to be considered for speculation. |
spark.locality.wait | 3000 | Number of milliseconds to wait to launch a data-local task before giving up and launching it on a less-local node. The same wait will be used to step through multiple locality levels (process-local, node-local, rack-local and then any). It is also possible to customize the waiting time for each level by setting spark.locality.wait.node, etc. You should increase this setting if your tasks are long and see poor locality, but the default usually works well. |
spark.locality.wait.process | spark.locality.wait | Customize the locality wait for process locality. This affects tasks that attempt to access cached data in a particular executor process. |
spark.locality.wait.node | spark.locality.wait | Customize the locality wait for node locality. For example, you can set this to 0 to skip node locality and search immediately for rack locality (if your cluster has rack information). |
spark.locality.wait.rack | spark.locality.wait | Customize the locality wait for rack locality. |
spark.scheduler.revive.interval | 1000 | The interval length for the scheduler to revive the worker resource offers to run tasks (in milliseconds). |
spark.scheduler.minRegisteredResourcesRatio | 0.0 for Mesos and Standalone mode, 0.8 for YARN | The minimum ratio of registered resources (registered resources / total expected resources) (resources are executors in yarn mode, CPU cores in standalone mode) to wait for before scheduling begins. Specified as a double between 0.0 and 1.0. Regardless of whether the minimum ratio of resources has been reached, the maximum amount of time it will wait before scheduling begins is controlled by config spark.scheduler.maxRegisteredResourcesWaitingTime. |
spark.scheduler.maxRegisteredResourcesWaitingTime | 30000 | Maximum amount of time to wait for resources to register before scheduling begins (in milliseconds). |
spark.localExecution.enabled | false | Enables Spark to run certain jobs, such as first() or take() on the driver, without sending tasks to the cluster. This can make certain jobs execute very quickly, but may require shipping a whole partition of data to the driver. |
BlockManager
Storagef 模块主要分为两层:
1):负责向 BlockManagerMaster 上报 blaock 信息,master 与 slave 之间的信息传递通 过 m - s 的模式传递
2):数据层 负责存储和读取信息,主要在 disk、memory、tachyon 上
通常 RDD 的数据存放在分区中,而 cache 的数据一般都是 block 中。所以 BlockManager 管理着所有的 Block。
BlockManeger 的构造成员:

初始化方法,有两个类容:1、注册 BlockManagerMaster,2、启动 BlockManagerWorker

Register BlockManger
注册 BlockManager 就是发送一个单向消息给 Master Actor。而这个消息参数则是一个 RegisterBlockManager 对象,实例化这个对象需要设置几个属性:id, maxMemSize, slaveActor

这里需要查看 tell 方法。源码如下:

Akka 是一个基于 scala 编写的分布式消息驱动框架。消息发送完后,BlockManagerMasterActor 会接收处理消息。BlockManagerMasterActor 是 Master 节点上的 Actor 来跟踪所有的 Slave 的 Block 的状态。接收注册的代码如下:

这里主要查看 register 方法:

以上代码描述了 Storage 在通讯层处理代码。
Stroage
Spark 在存储上主要提供了三种方案:

MemoryStore
基于内存的存储有两种一种是基于反序列化 java 对象数组和列化的 ByteBuffers。在 MemoyStore 中维护了一个 LinkedHashMap 对象,它是以 blockID 和 MemoryEntry 的 K / V 存储。
private valentries = new LinkedHashMap[BlockId, MemoryEntry](32, 0.75f, true)
存储方法主要包括两种 putBytes、putArray。在具体存储的时候需要根据 StorageLevel 的序列化属性 deserialized,对数据做不同的操作。当内存不够的时候,默认是写磁盘的。具体看下这两个方法:

首先看下 putIterator 方法:

这里不再一一介绍方法,下面看下读取主要方法:getBytes、getValues

读取 Block 主要传递 blockId 就行了。
DiskStore
将 block 存储到磁盘上。和 MemoryStroe 一样写入和读取都有两种方法 putBytes、putArray。源码如下:

TachyonStroe
Tachyon 是一个基于内存的分布式存储框架。这里的存储到 Tachyon 和 MemoryStroe 一样都有两种方法。

这里主要看 putIntoTachyonStore 方法

RDD API
在 Shuffle 过程中,为保持数据容错或者结构数据再次利用。RDD 提供了 cache、persist 来存储数据,在源码中可以看出其实 cache 就是调用了 persist。

StorageLevel
StotageLevel 标志着 Spark Storage 的存储级别。它的存储介质主要包括 Disk、Memory、OffHeap。另外还有 deserialized 标志数据序列化操作和 replication 副本数。在源码中默认为 1 个。下面从源码中阅读 StorageLevel。
CheckPoint
一般在程序运行比较长或者计算量大的情况下,需要进行 CheckPoint。这样可以避免在运行中出现异常导致代价过大的问题。CheckPoint 会把数据写在本地磁盘上。在进行 checkpoint 前的 RDD 数据需要进行 cache。因为 checkpoint 的时候会移除它的所有父节点信息,那麽在第二次加载的时候就不需要重新从磁盘加载数据。
在 Map 和 Reduce 之间的过程就是 Shuffle,Shuffle 的性能直接影响整个 Spark 的性能。所以 Shuffle 至关重要。
Shuffle 介绍

从图中得知,Map 输出的结构产生在 bucket 中。而 bucket 的数量是 map*reduce 的个数。这里的每一个 bucket 都对应一个文件。Map 对 bucket 书是写入数据,而 reduce 是对 bucket 是抓取数据也就是读的过程。
在 spark1.1.1 中 shuffle 过程的处理交给了 ShuffleBlockManager 来管理。
ShuffleManager
ShuffleManager 中有四个方法:
1)registerShuffleShuffle 注册
2)getWriter 获得写数据的对象
3)getReader 获得读取数据的对象
4)unregisterShuffle 移除元数据
5)Stop 停止 ShuffleManager
ShuffleManager 有两个子类:

Shuffle Write
Shuffle 写的过程需要落地磁盘。在参数

中可以配置。
接下来看下 write 的具体方法

如果 consolidateShuffleFiles 为 true 写文件,为 false 在 completedMapTasks 中添加 mapId。
接下来看下 recycleFileGroup 这个方法。参数 ShuffleFileGroup 是一组 shuffle 文件,每一个特定的 map 都会分配一组 ShuffleFileGroup 写入文件。代码如下:

这里的 valunusedFileGroups = new ConcurrentLinkedQueue[ShuffleFileGroup]() 是一个链表队列。往队列中添加 shuffleFileGroup
而在 shuffleState.comletedMapTasks 这个方法则是往 bucket 中填充,如果 consolidateShuffleFiles 为 FALSE,则不需要管他。源码中也是这样解释 completedMapTasks 这个队列:

源码中的 ShuffleState 是记录 shuffle 的一个特定状态。
ShuffleWrite 有两个子类:

HashShuffleWriter 中的写方法:

再来看下 SortShuffleWriter 的 write 方法:

ShuffleReader
HashShuffleReader

SortShuffleManager 中的读取对象调用了 HashShuffleReader

在 Spark1.1.1 源码中 SortShuffleManager 压根就没实现。
Shuffle partition
在 RDD API 中当调用 reduceByKey 等类似的操作,则会产生 Shuffle 了。

根据不同的业务场景,reduce 的个数一般由程序猿自己设置大小。可通过“spark.default.par allelism”参数设置。

1、在第一个 MapPartitionsRDD 这里先做一次 map 端的聚合操作。
2、ShuffledRDD 主要是做从这个抓取数据的工作。
3、第二个 MapPartitionsRDD 把抓取过来的数据再次进行聚合操作。
4、步骤 1 和步骤 3 都会涉及到 spill 的过程。
在作业提交的时候,DAGSchuduler 会把 Shuffle 的成过程切分成 map 和 reduce 两个部分。每个部分的任务聚合成一个 stage。
Shuffle 在 map 端的时候通过 ShuffleMapTask 的 runTask 方法运行 Task。

ShuffleMapTask 结束之后,最后走到 DAGScheduler 的 handleTaskCompletion 方法当中源码如下:

Stage 结束后,到 reduce 抓取过程。查看 BlockStoreShuffleFetcher 源码如下:

Broadcast 变量是 Spark 所支持的两种共享变量。主要共享分布式计算过程中各个 task 都会用到的只读变量。
广播变量允许程序员在每台机器上保持一个只读变量的缓存,而不是发送它的一个副本任务。他们可以用于:给一个大量输入数据集的副本以有效的拷贝到每个节点。Spark 也尝试使用高效广播算法来降低通信成本。
以下是源码结构:

Spark 目前提供了两种广播形式:
l HttpBroadcast:实现 HTTP Server 作为广播机制。第一次 HTTP 广播变量(发送一部分任务)反序列化执行。从 driver(在 driver 上执行的 HTTP Server)抓取广播数据,然后存储到 Block 中,以便下次更快速度访问
l TorrentBroadcast:一个 BT 实现。driver 将序列化对象划分一个个小块,教给 BlockManager 处理存储。每一个执行器 executor 将首先尝试从 BlockManager 获取的对象。如果没有找到,它然后使用远程从 driver 或者其他执行器抓取数据块。一旦它得到的这个数据块,它会把块在自己的 BlockManager,准备其他执行人从获取。
HttpBroadcast
实现 HTTP Server 作为广播机制。第一次 HTTP 广播变量(发送一部分任务)反序列化执行。从 driver(在 driver 上执行的 HTTP Server)抓取广播数据,然后存储到 Block 中,以便下次更快速度访问。
Initialize 方法:
源码如下:

1、在 driver 端创建 createServer。

1、创建定时器
MetadataCleaner 封装了一个定时器 TimerTask,用于定时清理元数据。
TorrentBroadcast
一种 BT 实现。driver 将序列化对象划分一个个小块,教给 BlockManager 处理存储。每一个执行器 executor 将首先尝试从 BlockManager 获取的对象。如果没有找到,它然后使用远程从 driver 或者其他执行器抓取数据块。一旦它得到的这个数据块,它会把块在自己的 BlockManager,准备其他执行人从获取。
Initialize:

Torrent 在此处没做什么,这也可以看出和 Http 的区别,Torrent 的处理方式就是 p2p,去中心化。而 Http 是中心化服务,需要启动服务来接受请求。
网络管理,由于分布式集群,那么无论 master 还是 worker 都离不开网络通讯。Network 包位于核心源码 org.apache.spark.network 中。
Connection
Connection 是一个抽象,它有两个子类 ReceivingConnection、SendingConnection。接收连接和发送连接。
ReceivingConnection
接收连接。这里面有几个比较中要的方法:getRemoteConnectionManagerId()、processConnectionManagerId(header: MessageChunkHeader)、read()
getRemoteConnectionManagerId():获取远程连接的消息 Id,这个方法调用了父类的实现。
processConnectionManagerId 源码如下:

这里面有个内部类 Inbox,它是一个消息存储集合。里面有个属性
val messages = new HashMap[Int,BufferMessage]()
所有连接到该节点的机器都会被记录到这个 messages 集合中。
SendingConnection
发送连接。它和 ReceivingConnection 恰恰相反。
ConnectionId
生成连接的 ID 对象。生成的原则包括:
override def toString =connectionManagerId.host + “_” + connectionManagerId.port +”_” + uniqId
ConnectionManager
ConnectionManager,顾名思义管理 connection。里面定义定了内部类 MessageStatus、配置参数还有一系列的线程池等等。
MessageStatus:消息状态,用于跟踪连接消息状态。
配置参数:

Netty
Server
BlockServer
BlockServer 服务器提供的 Spark 数据块。它有两层协议:
l C2S:用于请求 blocks 协议(客户端到服务器):按照目录结构
l S2C:用于请 blocks 协议(服务器到客户端)
frame-length (4bytes), block-id-length (4 bytes), block-id, block-data.
frame-length 不包括自身长度。如果 block-id-length 长度为负,那么这是一个错误消息,而不是块的数据。真正的长度是 frame-length 的绝对值。
下面是初始化 init 源码:



BlockServerHandler
BlockServerHandler 请求从客户端和写数据块 block 回来的处理程序。消息应已被 LineBasedFrameDecoder 处理和 StringDecoder 首次如此 channelRead0 被调用一次每行(即 block ID)。
Client
BlockFetchingClient
BlockFetchingClient 从 org.apache.spark.network.netty.server.BlockServer 抓取数据。
查看里面一个比较中要的方法:fetchBlocks。该方法向远程服务器的序列划 block,并执行回调。它是异步的,并立即返回。
源码如下:

Conf
Property Name | Default | Meaning |
spark.driver.host | (local hostname) | Hostname or IP address for the driver to listen on. This is used for communicating with the executors and the standalone Master. |
spark.driver.port | (random) | Port for the driver to listen on. This is used for communicating with the executors and the standalone Master. |
spark.fileserver.port | (random) | Port for the driver’s HTTP file server to listen on. |
spark.broadcast.port | (random) | Port for the driver’s HTTP broadcast server to listen on. This is not relevant for torrent broadcast. |
spark.replClassServer.port | (random) | Port for the driver’s HTTP class server to listen on. This is only relevant for the Spark shell. |
spark.blockManager.port | (random) | Port for all block managers to listen on. These exist on both the driver and the executors. |
spark.executor.port | (random) | Port for the executor to listen on. This is used for communicating with the driver. |
spark.port.maxRetries | 16 | Default maximum number of retries when binding to a port before giving up. |
spark.akka.frameSize | 10 | Maximum message size to allow in “control plane” communication (for serialized tasks and task results), in MB. Increase this if your tasks need to send back large results to the driver (e.g. using collect() on a large dataset). |
spark.akka.threads | 4 | Number of actor threads to use for communication. Can be useful to increase on large clusters when the driver has a lot of CPU cores. |
spark.akka.timeout | 100 | Communication timeout between Spark nodes, in seconds. |
spark.akka.heartbeat.pauses | 6000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). Acceptable heart beat pause in seconds for akka. This can be used to control sensitivity to gc pauses. Tune this in combination of `spark.akka.heartbeat.interval` and `spark.akka.failure-detector.threshold` if you need to. |
spark.akka.failure-detector.threshold | 300.0 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). This maps to akka’s `akka.remote.transport-failure-detector.threshold`. Tune this in combination of `spark.akka.heartbeat.pauses` and `spark.akka.heartbeat.interval` if you need to. |
spark.akka.heartbeat.interval | 1000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). A larger interval value in seconds reduces network overhead and a smaller value (~ 1 s) might be more informative for akka’s failure detector. Tune this in combination of `spark.akka.heartbeat.pauses` and `spark.akka.failure-detector.threshold` if you need to. Only positive use case for using failure detector can be, a sensistive failure detector can help evict rogue executors really quick. However this is usually not the case as gc pauses and network lags are expected in a real Spark cluster. Apart from that enabling this leads to a lot of exchanges of heart beats between nodes leading to flooding the network with those. |
Spark 的监测系统。
配置文件在目录~/spark-1.1.0-bin-Hadoop2.4/conf/metrics.properties.template 下。
这个配置文件是主要针对 Spark 内部组件监测的一个配置项。它可以配置一个或多个 sinks。一下是 metrics 的一些基本属性概念
“instance”指定“who”(角色)使用的指标体系。配置的实例可以是 ”master”, “worker”, “executor”,”driver”, “applications”。这些角色将创建指标系统来监测。所以这些实例等于这些角色。
“source”指定“where”(来源)收集的数据指标。在指标体系中,存在两种来源:
1、Spark 内部 source,像的 MasterSource,WorkerSource 等,它们会接收 Spark 组件的内部状态。这些 source 都与实例是创建特定的指标体系后,被添加的。
2、常见的 source,就像 JvmSource,这将低水平状态的收集,是由配置项决定的,并通过反射加载。
“sink”指定“where”(目的地)输出指标数据。多个 sinks 可以共存并冲洗指标对所有这些汇总。
Metrics 配置如下:
[instance].[sink|source].[name].[options] =xxxx
[instance] 可以是 ”master”, “worker”, “executor”,”driver”, “applications”,这意味着只有指定的实例才有这个属性。可用通配符“*”来代替实例名,这意味着所有的实例将具有这种属性。
[sink|source] 表示该属性是 source 或者 sink。此字段只能是 source or sink。
[name] 指定 sink or source 的名称,它是自定义的
[options] 这是 source or sink 的特定属性。
配置注意项:
1、添加一个新的 sink,需要设置一个符合规范的 class 类名选项
2、Sink 设置的轮询周期至少是一秒
3、指定名称的具体设置会覆盖带 * 号的,比如 master.sink.console.period 优先于
*.sink.console.period.
4、Metrics 具体配置。如:spark.metrics.conf=${SPARK_HOME}/conf/metrics.properties 必须添加 java 的参数如 -Dspark.metrics.conf=xxx。如果把文件放在 ${SPARK_HOME}/conf 目录下,它会自动加载。
5、在 master, worker and client driver 的 sinks 的默认添加方式是 MetricsServlet 处理。发送请求参数“/metrics/json”以 josn 的格式注册 metrics。对于 master 可以发送“/metrics/mastern/json”获取 master 实例和 app。
Metrics 配置案例:
# org.apache.spark.metrics.sink.ConsoleSink # Name: Default: Description: # period 10 Poll period # unit seconds Units of poll period
# org.apache.spark.metrics.sink.CSVSink # Name: Default: Description: # period 10 Poll period # unit seconds Units of poll period # directory /tmp Where to store CSV files
# org.apache.spark.metrics.sink.GangliaSink # Name: Default: Description: # host NONE Hostname or multicast group of Ganglia server # port NONE Port of Ganglia server(s) # period 10 Poll period # unit seconds Units of poll period # ttl 1 TTL of messages sent by Ganglia # mode multicast Ganglia network mode (‘unicast’ or ‘multicast’)
# org.apache.spark.metrics.sink.JmxSink
# org.apache.spark.metrics.sink.MetricsServlet # Name: Default: Description: # path VARIES* Path prefix from the web server root # sample false Whether to show entire set of samples for histograms (‘false’ or ‘true’) # # * Default path is /metrics/json for all instances except the master. The master has two paths: # /metrics/aplications/json # App information # /metrics/master/json # Master information
# org.apache.spark.metrics.sink.GraphiteSink # Name: Default: Description: # host NONE Hostname of Graphite server # port NONE Port of Graphite server # period 10 Poll period # unit seconds Units of poll period # prefix EMPTY STRING Prefix to prepend to metric name
## Examples # Enable JmxSink for all instances by class name #*.sink.jmx.class=org.apache.spark.metrics.sink.JmxSink
# Enable ConsoleSink for all instances by class name #*.sink.console.class=org.apache.spark.metrics.sink.ConsoleSink
# Polling period for ConsoleSink #*.sink.console.period=10
#*.sink.console.unit=seconds
# Master instance overlap polling period #master.sink.console.period=15
#master.sink.console.unit=seconds
# Enable CsvSink for all instances #*.sink.csv.class=org.apache.spark.metrics.sink.CsvSink
# Polling period for CsvSink #*.sink.csv.period=1
#*.sink.csv.unit=minutes
# Polling directory for CsvSink #*.sink.csv.directory=/tmp/
# Worker instance overlap polling period #worker.sink.csv.period=10
#worker.sink.csv.unit=minutes
# Enable jvm source for instance master, worker, driver and executor #master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
#worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
#driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
#executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
|
MetricsSystem
主要查看如下三个方法:

Initialize 加载默认配置项,源码如下:

registerSources:

进入 registerSource

继续:register
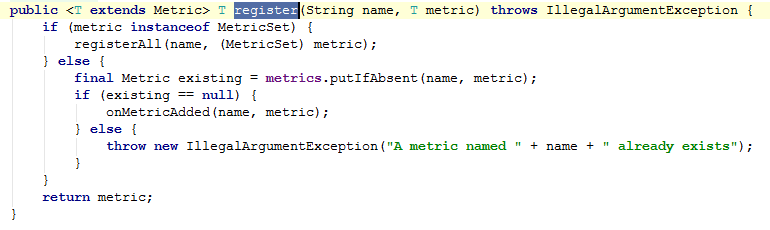

MetricRegistryListener 是个监听器。
这里面的监听就包括添加、移除监听器等。
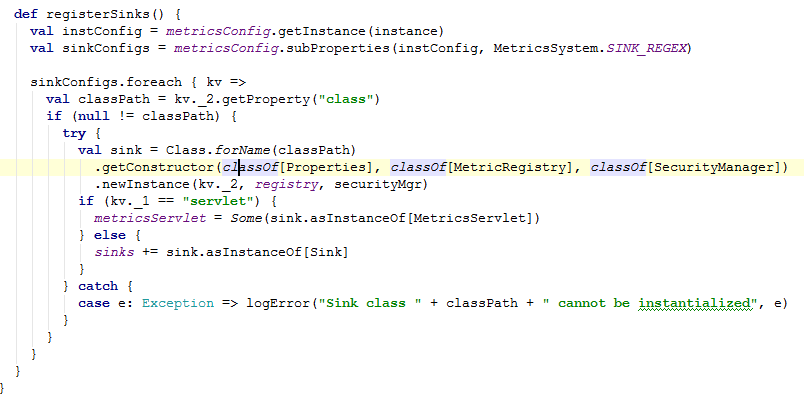
registerSinks 方法
Source
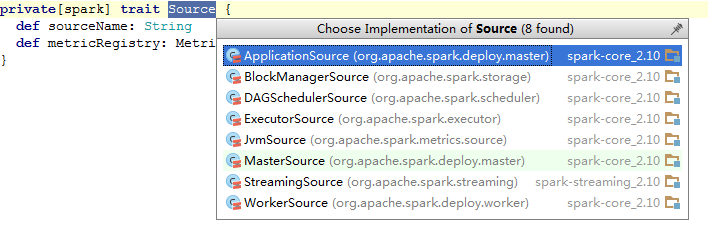
ApplicationSource
Application 注册了 status、runtime_ms、cores
BlockManagerSource
BlockManager 注册了 maxMem_MB、remainingMem_MB、memUsed_MB、diskSpaceUsed_MB
DAGSchedulerSource
DAGScheduler 注册了 failedStages、runningStages、waitingStages、allJobs、activeJobs
ExecutorSource
Executor 注册了 activeTasks、completeTasks、currentPool_size、maxPool_size 等
MasterSource
Master 上注册了 workers、apps、waitingApps
StreamingSource

WorkerSource

首先需要修改配置文件 spark-env.sh。在这个文件中需要添加两个属性:
Export Hadoop_HOME=/../hadoop..
ExportHADOOP_CONF_DIR=/../hadoop/etc/hadoop
这里,一个是要 hadoop 的 home 目录。一个是配置文件目录。
还需要配置一个就是 spark-defaults.conf 这个文件:

需要修改红色框内的文件。下面看下这个文件里面的内容:

在 spark 的源文件中给出了一些配置参数的示例。另外它还下面一个可以配置的属性
属性名 | 说明 | 默认值 |
spark.yarn.applicationMaster.waitTries | RM 等待 Spark AppMaster 启动次数,也就是 SparkContext 初始化次数。超过这个数值,启动失败。 | 10 |
spark.yarn.submit.file.replication | 应用程序上载到 HDFS 的文件的复制因子 | 3 |
spark.yarn.preserve.staging.files | 设置为 true,在 job 结束后,将 stage 相关的文件保留而不是删除。 | false |
spark.yarn.scheduler.heartbeat.interval-ms | Spark AppMaster 发送心跳信息给 YARN RM 的时间间隔 | 5000 |
spark.yarn.max.executor.failures | 导致应用程序宣告失败的最大 executor 失败数 | 2 倍于 executor 数 |
spark.yarn.historyServer.address | Spark history server 的地址(不要加 http://)。这个地址会在应用程序完成后提交给 YARN RM,使得将信息从 RM UI 连接到 history server UI 上。 | 无 |
还有更多的配置内容参考 http://blog.csdn.net/book_mmicky/article/details/29472439。这里不一一列举。
运行流程
下面是 Spark On Yarn 的流程图:

上图比较只管的看到到了流程,下面具体看几个源码
Client
在 Client 类中的 main 方法实例话 Client:new Client(args, sparkConf).run()。在 run 方法中,又调用了 val appId = runApp() 方法。runApp() 源码如下:
def runApp() = { validateArgs()
init(yarnConf) start() logClusterResourceDetails()
val newApp = super.getNewApplication() val appId = newApp.getApplicationId()
verifyClusterResources(newApp) val appContext = createApplicationSubmissionContext(appId) val appStagingDir = getAppStagingDir(appId) val localResources = prepareLocalResources(appStagingDir) val env = setupLaunchEnv(localResources, appStagingDir) val amContainer = createContainerLaunchContext(newApp, localResources, env)
val capability = Records.newRecord(classOf[Resource]).asInstanceOf[Resource] // Memory for the ApplicationMaster. capability.setMemory(args.amMemory + memoryOverhead) amContainer.setResource(capability)
appContext.setQueue(args.amQueue) appContext.setAMContainerSpec(amContainer) appContext.setUser(UserGroupInformation.getCurrentUser().getShortUserName())
submitApp(appContext) appId } |
1)这里首先对一些参数配置的校验,然后初始化、启动 Client
2)提交请求到 ResouceManager,检查集群的内存情况。
3)设置一些参数,请求队列
4)正式提交 APP
ApplicationManager
AM 负责运行 Spark Application 的 Driver 程序,并分配执行需要的 Executors。里面也有个 main 方法实例化 AM 并调用 run,源码如下:























